Intro
Recently, I passed the AWS SAA certification, and while sharing your achievement on socials after long months of preparation and grind can be gratifying, some Pearson Vue test takers, didn’t have the same smooth experience, for unexpected challenges due to OnVue software glitches.
In this short post, I’ll take you through the surreal blunders of my proctored exam stint and share some tips to help you navigate the technical nightmare I went through with OnVue software on my exam. strap in!!
Note: I had this with on Windows with a dell XPS laptop but it could be any setup.
I. Day 1: Houston, We've Got a Problem!
System test failed (Exam Rescheduled)
1. OnVue: Microphone undetected
Here’s the deal, I’m all set up and ready to knock out this proctored test from home. I checked in early, my gear’s all set, I download the OnVue software but right when I run the first check—it’s like it’s got a beef with my mic. My mic's good, I checked it a hundred times, works like a charm every time, but for OnVue? nada! almost acting like my mic’s invisible.

I’m on the line with support, trying to fix this mess myself after I was told to use another laptop.Time runs out, but no dice. They say we’ll need to reschedule (◡︵◡).
I don’t blame the support folks but PearsonVue’s management of their software patching is ridiculous. What’s next ! a laptop fleet to write an online exam?
Solution
After a couple hours of digging around on Google and trying every fix I could find, I finally cracked it. Here’s what you gotta do if OnVue’s complaining about your Mic.
Hit the Windows key + R to fire up the Run box.
Punch in mmsys.cpl and smack Enter. This pops open the Sound window.
Click over to the Recording tab. Look for your microphone—it should have a green tick next to it.
Right-click the mic, hit Properties, then move over to the Levels tab.
Crank that volume up to the max. See a red symbol on the speaker icon? Click that "mute" symbol to get rid of it if it’s checked.
See picture below :
2. OnVue: Video Streaming issues
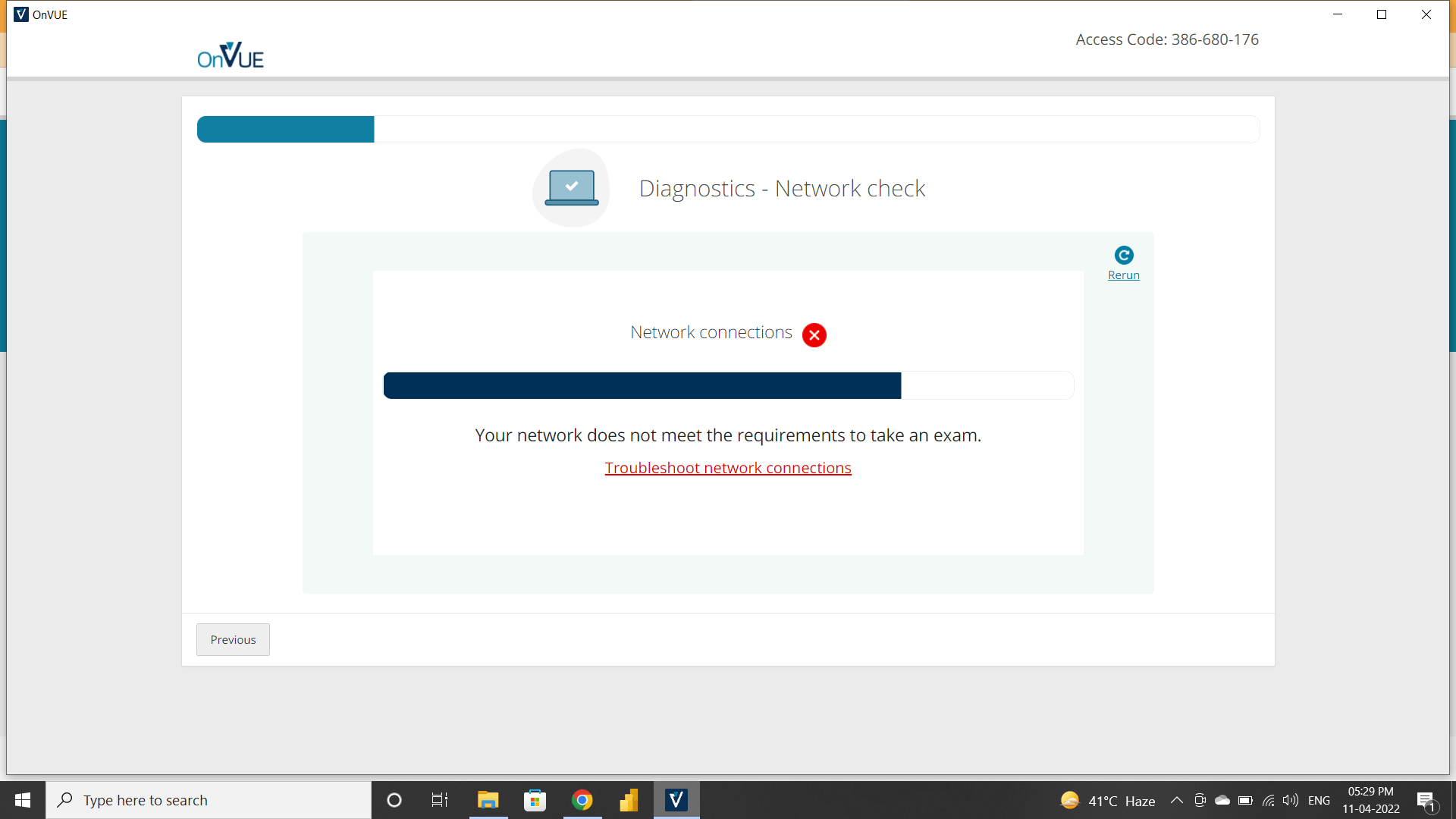
Just when I thought I was out of the woods with the mic issue, bam, the video streaming starts acting up. In the middle of the system test, the above error popped up during the Diagnostics - Network check.
Now, you might think it's a bandwidth problem, right? Wrong.That’s just a red herring.

The first part of the error shows the below:
“The streaming connection requires that Wowza.com can be reached as well as a stable connection of at least 1mb upload and download speeds.”
So I run a quick Speedtest, and my internet’s hitting 300 Mbps, so no problems there. Something else was off.
But at the bottom of the message, I noticed this line:
“..ensure any network filtering software is disabled..
WebRTC WebSocket connections must be allowed to *.*.cloud.wowza.com on TCP port 80, 443, 1935.”
Solution
So, it’s not just about speed—it’s about reaching Wowza.com. When installing OnVue, a pop-up asks you to create firewall rules for *cloud.wowza.com.
If you missed or ignored this, you have two ways to fix it.
Option 1:
Do it manually through windows firewall as explained in this tutorial manually-open-ports-in-windows-firewall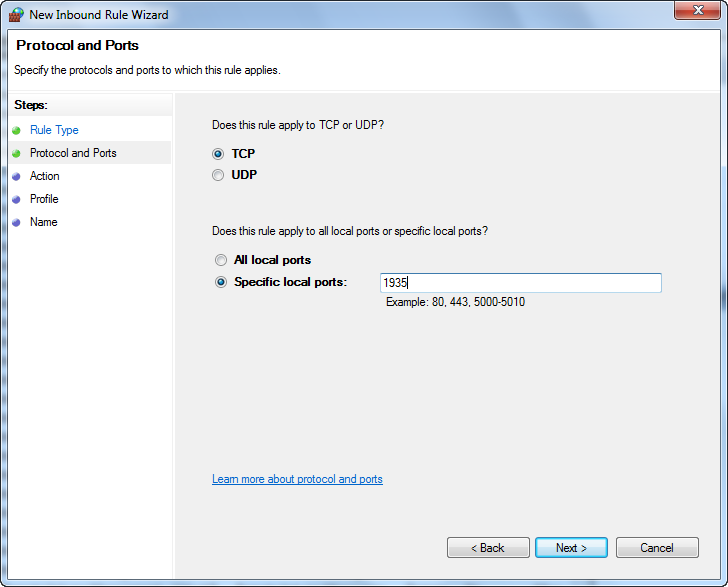
Option2:
Just re-run the installer again which show you the pop up so you can let OnVue to add the rules automatically
II. Day 2: Second Attempt - OnVue App Goes Nuts
OneVue App Froze 1 Minute Before Final Submission
Nightmare
Picture this: I answered all my questions in an hour and started reviewing them. In the last minute, a crazy pop-up shows up, telling me an application is still running, which could revoke my exam. I barely had time to think. I quickly try to close it to keep the proctor off my back. But guess what? The exam freezes completely.

Nothing's working. I'm sitting there, shocked, wondering if my time's still ticking or if the proctor's pulled the plug on me. Not a single clue.
The app in question? WhatsApp. But windows store apps like WhatsApp don't show up in Task Manager like other processes. And to make matters worse, the system check didn't even spot it when I checked in. Maybe it woke up later, who knows? Anyway, I was stuck.I call support, and what do they tell me? Just wait for the OnVue screen to unfreeze. Completely useless.
Solution
I nearly lost it, but then I decided to take a chance. I closed Chrome, where my session was being recorded, and restarted the OnVue software with the same Access Code.
The system check was okay, so I got back into the exam queue. The proctor greeted me, and I acted like it was my first time. I figured, at worst, I'd have to retake the exam :).
I didn't say a word to the proctor, and then—poof—my previous session came back. All my answers were there, with 30 seconds left on the clock. I hit send, and the rest is history! I passed the exam :).
TAKEAWAYS
System Test Failures: Run thorough system checks well in advance many times.
Microphone Issues: Adjust settings via Windows sound properties.
Video Streaming Problems: Confirm firewall rules and re-run the installer.
Handling Background Apps: Close or uninstall all unnecessary apps from windows store
App Freezing: Restart OnVue browser after calling support and try checking with same access code
Close other user sessions open in the computer: applies to Mac too (siri is not welcome)
Stay Calm Under Pressure: Contact support and act quickly to regain control.
AWS PearsonVue Hotline : 866-207-9983 (Americas) , worldwide check here.