-- “Because sh*t happens, be ready for when it does!” --
Intro

Infrastructure Automation is a lifesaver for OPS teams in their day-to-day duties, but when it comes to givin' full control to new tools and frameworks, watch out for problems that can no longer be fixed manually. It’s also a reminder that it is easier to create a mess than to clean it.
Today, we'll show you how to recover from a failed Terraform apply when half of the resources have already been provisioned, but an error occurred in the middle of the deployment. This can be especially challenging if you have a large number of resources, and you can't destroy them either in the console or through Terraform destroy. Not to mention all them $$ that your Cloud will keep charging for the unusable resources, yikes!
I. How did the Terraform Apply Crash happen

How did I get here? It was not even my code, I was actually just minding my business tryin' to spin up a Fortinet firewall in Oracle Cloud using their reference architecture (oracle-quickstart).
Here’s a link to the GitHub repo I used but the code is not relevant at all. These config errors can happen anytime.
https://github.com/oracle-quickstart/oci-fortinet/drg-ha-use-case
The scenario is simple:
Clone the GitHub repository that contains the terraform configuration
Adjust the authentication parameters such as your API keys for the OCI environment etc
Run the terraform init command
Run the terraform plan command to make sure everything looks good
$ cd ~/forti-firewall/oci-fortinet/use-cases/drg-ha-use-case$ terraform init
$ terraform -v
Terraform v1.0.3
+ provider registry.terraform.io/oracle/oci v4.105.0
+ provider registry.terraform.io/hashicorp/template v2.2.0$ terraform plan
…
Plan: 66 to add, 0 to change, 0 to destroy.All the plan checks come back positive, we're ready to go! let’s focus on the apply
$ terraform apply -–auto-approve
oci_core_drg.drg: Creating...
oci_core_vcn.web[0]: Creating...
oci_core_app_catalog_listing_resource_version_agreement.mp_image_agreement[0]: Creating...
oci_core_vcn.hub[0]: Creating...
oci_core_vcn.db[0]: Creating...
oci_core_drg_attachment.db_drg_attachment: Creation complete after 14s oci_core_drg_route_distribution_statement.firewall_drg_route_distribution_statement_two: Creating... oci_core_drg_route_distribution_statement.firewall_drg_route_distribution_statement_one: Creation complete after 1soci_core_drg_route_distribution_statement.firewall_drg_route_distribution_statement_two: Creation complete after 1s
oci_core_drg_route_table.from_firewall_route_table: Creation complete after 23s [id=ocid1.drgroutetable.oc1.ca-toronto-1.aaaaaaaag3ohsxxxxxxxxxxxxnykq]
│ Error: Invalid index │ │ on network.tf line 240, in resource "oci_core_subnet" "mangement_subnet": │ 240: security_list_ids = [data.oci_core_security_lists.allow_all_security.security_lists[0].id] │├──────────────── ││ data.oci_core_security_lists.allow_all_security.security_lists is empty list of object │ The given key does not identify an element in this collection value: the collection │has no elements.
...
SURPRISE !!!
Despite our successful terraform plan, our deployment was halted few minutes later due to the below error 
Now, If want to fix my code issue, a clean wipe out is the only way to go (terraform destroy), but is it possible?
Not even close:
The deployment stopped half way through with blocking errors
It’s really stuck, as we can't terraform destroy to undo our changes, nor can we proceed further
The plan is a mess because the dependency is now a mess (data source element empty etc)
The section below, explains why
II. Obvious cleanup options and outcomes (how’d it go?)
Terraform Destroy: Doesn’t work, still getting the same data source error so it’s stuck
$ terraform destroy --auto-approveoci_core_vcn.hub[0]: Refreshing state... [id=ocid1.vcn.oc1.ca-toronto-1xxx]
oci_core_network_security_group_security_rule.rule_ingress_all: Refreshing state... [id=F44A50] oci_core_network_security_group_security_rule.rule_egress_all: Refreshing state... [id=B14C98]
... │ Error: Invalid index │ │on network.tf line 240, in resource "oci_core_subnet" "mangement_subnet": │240: security_list_ids = [data.oci_core_security_lists.allow_all_security.security_lists[0].id] │├──────────────── ││ data.oci_core_security_lists.allow_all_security.security_lists is empty list of object
…2 more occurrence of the same error on 2 other security lists data sourceDestroy from the Console: Same, Resources can’t be destroyed no matter what order I chose.

I used the super handy OCI Tenancy Explorer which was suggested to me by Suraj Ramesh in twitter
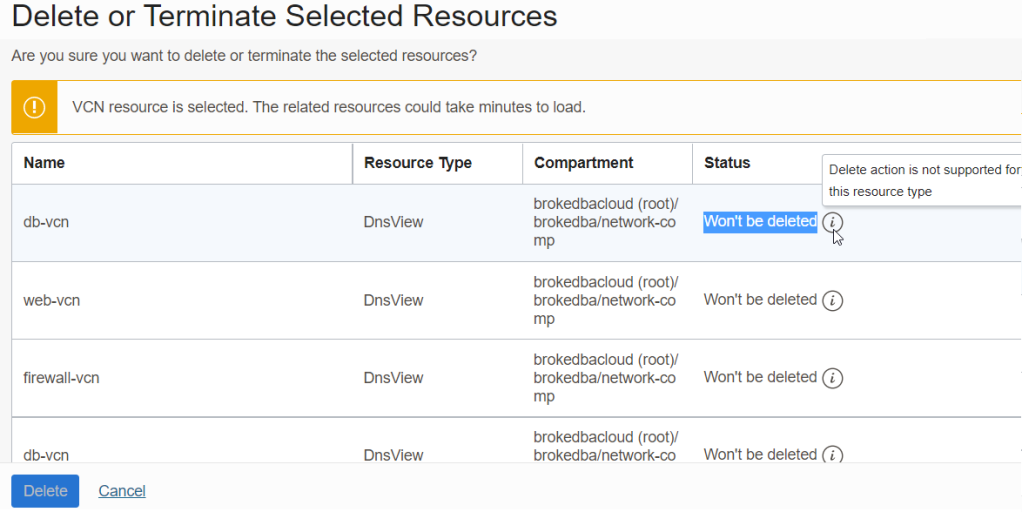
The OCI Console kept showing "Won't be deleted" and delete button was even grayed out due to dependency.
II. Root Cause of the Crash
All right so the situation is clear it’s stale mate, but we can already infere the below conclusions
Fetching an empty list from a data source in a resource block can cause a deployment to fail miserably
`terraform plan` could never detect such errors because it can only be known during the apply
terraform doesn’t have a failsafe mode that allows to recover when such buggy thing happens
data source are to be used with caution :)
-- “Time to switch to the hacking mode!” --
III. Solution
After hours of toiling to find a way to get outta this jam, I understood I wouldn't be able to fix the terraform error while I was mired in the swamp. I had to find a way to get back to square one,which led me to the below fix.
ALL YOU CAN TAINT:
"terraform taint" is a command used to mark a resource as 'tainted' in the state file.This will force the next apply to destroy and recreate of the resource. This is cool but to taint all the resources created so I came up with a bulk command using state list to do that (to taint 33 resources.)
$ terraform state list | grep -v ^data | xargs -n1 terraform taint
Resource instance oci_core_drg.drg has been marked as tainted.
Resource instance oci_core_drg_attachment.db_drg_att has been marked as tainted.
…
Resource instance oci_core_vcn.db[0] has been marked as tainted.
Resource instance oci_core_vcn.hub[0] has been marked as tainted.
Resource instance oci_core_vcn.web[0] has been marked as tainted.
Resource instance oci_core_volume.vm_volume-a[0] has been marked as tainted.
Resource instance oci_core_volume.vm_volume-b[0] has been marked as tainted.
...33 resources tainted in totalThis bulk taint allows do cleanup all the created resources through terraform destroy after an implicit refresh.
$ terraform destroy --auto-approve
oci_core_drg.drg: Refreshing state... [id=ocid1.xxx] oci_core_vcn.hub[0]: Refreshing state... [id=ocid1.vcn.oc1.ca-toronto-1.xxx]
...
Plan: 0 to add, 0 to change, 33 to destroy.
oci_core_route_table.ha_route_table[0]: Destroying
...
Destroy complete! Resources: 33 destroyed.
Having all resources wiped out by terraform, we can now begin anew with a clean slate.
IV. What If I Deployed Using Oracle Cloud Resource Manager ?
Resource Manager is an OCI solution that enables users to manage, provision, and govern their cloud resources.
It has a unified view of all deployed resources using Terraform under the hood. A deployment is called a stack were we can load our terraform configuration to automate and orchestrate deployments (plan-apply-destroy).
This makes sense if you want to keep your deployment configurations centralized in your cloud.

The used repository had even a link to deploy it from OCI Resource manager as shown above
Note: Other Cloud providers offer similar service but they have their own IaC language which is not Terraform..
Solution: Exporting the State and Tainting
If you were running your terraform apply from OCI Resources manager. Then you would have to:
1. Download the configuration from RM (or clone from Github)
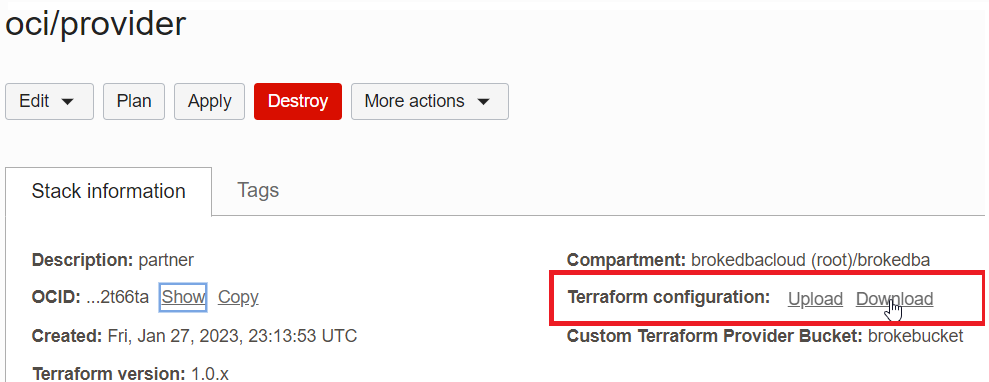
2. Import the state file directly from RM see below (Import State)

Important: Load both the terraform configuration(unzipped) and the state file in the same directory
3. Taint your resources: after an init and refresh all resources in the cloud are visible you can start tainting them
If you were running your terraform apply from OCI Resources manager. Then you would have to:
3. Taint your resources: after an init and refresh all resources in the cloud are visible you can start tainting them
$ cd ~/exported_location/drg-ha-use-case
$ terraform init
$ terraform refresh
$ terraform state list | grep -v ^data | xargs -n1 terraform taint
... # all resources are now tainted
# Destroy the resources
$ terraform destroy --auto-approve
Destroy complete! Resources: 33 destroyed.
$ cd ~/exported_location/drg-ha-use-case
$ terraform init
$ terraform refresh
$ terraform state list | grep -v ^data | xargs -n1 terraform taint
... # all resources are now tainted
# Destroy the resources
$ terraform destroy --auto-approve
Destroy complete! Resources: 33 destroyed.
CONCLUSION
We just learned how to quickly remediate a Terraform deployment that got stuck due to a blocking error.
Although terraform doesn’t have a failsafe mode, we can still leverage `taint` in similar failure cases.
I also got to code review :) third party terraform configs (opened and answered 2 issues for this stack)
Before loading your deployment into Resource Manager, It’s important to deploy/test it locally first (better for troubleshooting .i.e taint)
The logical error behind the failure? a mistake from the maintainers (wrong data source compartment)
`taint` is rather deprecated , HashiCorp recommends using the -replace option with terraform apply
$ terraform apply -replace="aws_instance.example[0]”