Intro
Every time I think I’m done with my ZDM troubleshooting series, a new topic pops up :). I have also learned that every migration is distinct and brings its own unique challenges, so I have decided to keep the series open-ended. In this post, we will discuss the steps you should take when a conversion of a non-CDB to a PDB fails during a ZDM migration to identify the root cause, and get your migration back on track. So, let's dive in!
Note: you ca always explore the other ZDM troubleshooting related post below:
- Migration failing at ZDM_CONFIGURE_DG_SRC
- Migration failing at ZDM_SWITCHOVER_SRC plus hack
My ZDM environment
ZDM: 21.3 build
| Property | Source | Target |
| RAC | NO | YES |
| Encrypted | NO | YES |
| CDB | NO | YES |
| Release | 12.2 | 12.2 |
| Platform | On prem Linux | ExaCC |
Prerequisites
All the prerequisites related to the ZDM VM, the Source and Target Database system were satisfied before running the migration.
Responsefile
Prepare a responsefile for a Physical Online Migration with the required parameters (see excerpt). I will just point out that ZDM 21.3 now supports Data Guard Broker configuration .
$ cat physical_online_demo.rsp | grep -v ^#
TGT_DB_UNIQUE_NAME=TGTCDB
MIGRATION_METHOD=ONLINE_PHYSICAL
DATA_TRANSFER_MEDIUM=DIRECT
PLATFORM_TYPE=EXACC
...etc
Run migration until the DG config –step1
Run migration until the DG config –step1
As usual Irun the migrate command with the -pauseafter ZDM_CONFIGURE_DG_SRC to stop when the replication is configured in order to resume the full migration a later time.
$ZDM_HOME/bin/zdmcli migrate database –sourcedb SRCDB \ -sourcenode srcHost -srcauth zdmauth \ -srcarg1 user:zdmuser \ -targetnode tgtNode \ -tgtauth zdmauth \ -tgtarg1 user:opc \ -rsp ./physical_online_demo.rsp –ignore ALL -pauseafter ZDM_CONFIGURE_DG_SRC
Resume migration –step2
Now that the Data guard Configuration is complete. It’s time to resume the full migration to the end.
$ zdmservice resume job –jobid 1
Querying job status
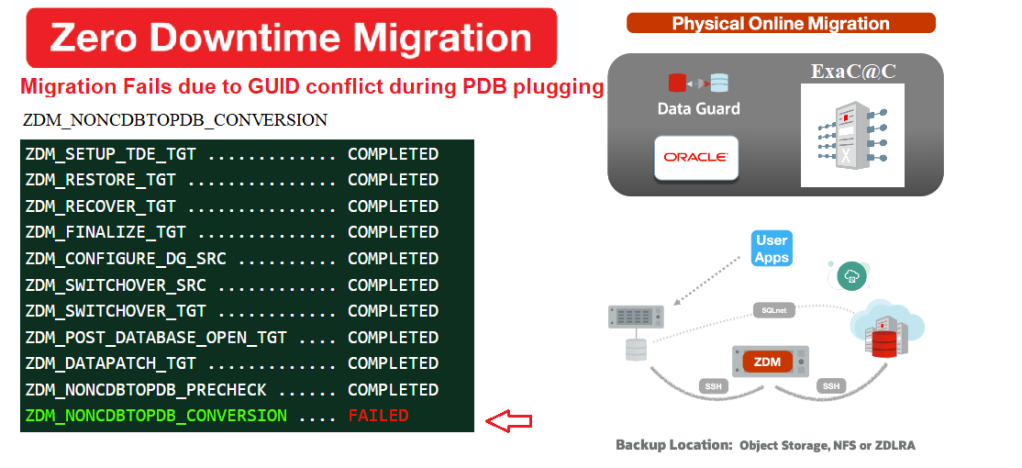
As you can see, It didn’t take long before noticing that the Switchover step failed.
$ zdmservice query job –jobid 1
zdmhost.domain.com: Audit ID: 39
Job ID: 1
User: zdmuser
Client: zdmhost
Job Type: "MIGRATE"
Current status: FAILED
Result file path: "/u01/app/oracle/zdmbase/chkbase/scheduled/job-1-*log" ...
Job execution elapsed time: 1 hours 25 minutes 41 seconds
ZDM_GET_SRC_INFO .............. COMPLETED
ZDM_GET_TGT_INFO .............. COMPLETED
ZDM_PRECHECKS_SRC ............. COMPLETED
ZDM_PRECHECKS_TGT ............. COMPLETED
ZDM_SETUP_SRC ................. COMPLETED
ZDM_SETUP_TGT ................. COMPLETED
ZDM_PREUSERACTIONS ............ COMPLETED
ZDM_PREUSERACTIONS_TGT ........ COMPLETED
ZDM_VALIDATE_SRC .............. COMPLETED
ZDM_VALIDATE_TGT .............. COMPLETED
ZDM_DISCOVER_SRC .............. COMPLETED
ZDM_COPYFILES ................. COMPLETED
ZDM_PREPARE_TGT ............... COMPLETED
ZDM_SETUP_TDE_TGT ............. COMPLETED
ZDM_RESTORE_TGT ............... COMPLETED
ZDM_RECOVER_TGT ............... COMPLETED
ZDM_FINALIZE_TGT .............. COMPLETED
ZDM_CONFIGURE_DG_SRC .......... COMPLETED
ZDM_SWITCHOVER_SRC ............ COMPLETED
ZDM_SWITCHOVER_TGT ............ COMPLETED
ZDM_POST_DATABASE_OPEN_TGT .... COMPLETED
ZDM_DATAPATCH_TGT ............. COMPLETED
ZDM_NONCDBTOPDB_PRECHECK ...... COMPLETED
ZDM_NONCDBTOPDB_CONVERSION .... FAILED
ZDM_POST_MIGRATE_TGT .......... PENDING
ZDM_POSTUSERACTIONS ........... PENDING
ZDM_POSTUSERACTIONS_TGT ....... PENDING
ZDM_CLEANUP_SRC ............... PENDING
ZDM_CLEANUP_TGT ............... PENDING
Troubleshooting the error
To determine the content of the error message, the best approach is to check the $ZDM_BASE logs hosted locally on the target node “$ORACLE_BASE/zdm/zdm_targetDB_$jobID/zdm/log”
-- Target node
$ cd $ORACLE_BASE/zdm/zdm_TGTCDB_1/zdm/log$ tail ./zdm_noncdbtopdb_conversion_*.log
… [jobid-1][2022-12-14][mZDM_Queries.pm:556]:[DEBUG] Output is :
SQL*Plus: Release 12.2.0.1.0 Production on Wed Dec 14 2022 ..
Connected to: Oracle Database 12c EE Extreme Perf Release 12.2.0.1.0 - 64bit Production
CREATE PLUGGABLE DATABASE zdm_aux_SRCDB using '/tmp/zdm_aux_SRCDB.xml' NOCOPY
TEMPFILE REUSE* ERROR at line 1:
ORA-65122: Pluggable database GUID conflicts with the GUID of an existing container.
[jobid-1][2022-12-14][mZDM_convert_noncdb2pdb.pl:522]:[ERROR]
failed to create the PDB 'zdm_aux_SRCDB'
As you can see above, the issue is related to the new PDB created in the target CDB from the auxiliary database
What Happened
In an online physical migration from a non-CDB database to a PDB on a target container, ZDM creates an auxiliary standby database in the background to ensure replication consistency before the final switchover. After the switchover is complete, a data patch is applied and an unplug and plug operation is done to convert the auxiliary DB into a PDB on the target container database (CDB).
Why is ZDM failing to create the new PDB?
Turns out, ZDM attempted to construct a new PDB from the generated XML manifest but was unsuccessful, as Oracle had assigned a default GUID from another PDB in the CDB. I wouldn't say this happens for all instances of target CDBs with existing PDBs (I already completed such migrations in the past), but in this case, two databases had already been migrated to the same target CDB before this one.
Subsidiary question
Why did the CREATE PLUGGABLE DATABASE command use an existing GUID instead of generating a new one?
I don’t have the answer to this yet but we chose to open an SR and see if there was a workaround for this issue.
SOLUTION: ZDM pl script rewrite
Force ZDM to use the clone option :
ZDM uses a PDB plugin script called mZDM_convert_noncdb2pdb.pl to perform the PDB conversion
All we need to do is to update the script at the plugin section and add AS CLONE to the create pluggable database command
Location : Make a copy of the below file on he ZDM host before the change
cp $ZDM_HOME/rhp/zdm/mZDM_convert_noncdb2pdb.pl mZDM_convert_noncdb2pdb.pl.old
The perl script contains variables replacing the PDB name & XML manifest, but the error here occurred because the script had a "NOCOPY" statement without an "AS CLONE" clause.
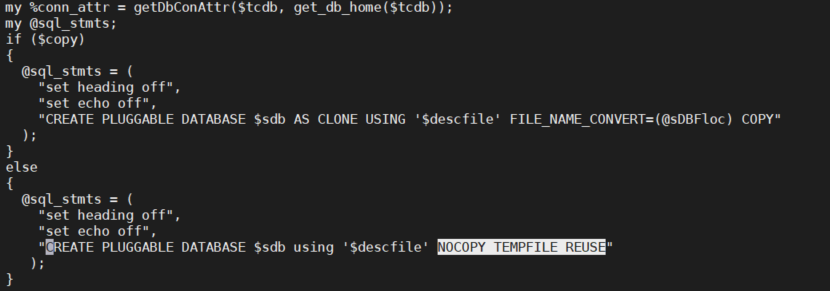 To fix the issue, we just need amend it and add the missing clone part.
To fix the issue, we just need amend it and add the missing clone part.
…else
{
@slq_stmts =(
...
“CREATE PLUGGABLE DATABASE $sdb AS CLONE USING '$descfile' NOCOPY TEMPFILE REUSE”);
}
Note:
It is only advised to perform the below change in this particular case or when asked by Oracle support.
Resume the job
this is it, ZDM will now create the PDB as clone implying a new GUID after resuming the job to complete the rest of our online physical migration
$ zdmservice resume job –jobid 1
$ zdmservice query job –jobid 1
...
ZDM_CONFIGURE_DG_SRC .......... COMPLETED
ZDM_SWITCHOVER_SRC ............ COMPLETED
ZDM_SWITCHOVER_TGT ............ COMPLETED
ZDM_POST_DATABASE_OPEN_TGT .... COMPLETED
ZDM_DATAPATCH_TGT ............. COMPLETED
ZDM_NONCDBTOPDB_PRECHECK ...... COMPLETED
ZDM_NONCDBTOPDB_CONVERSION .... COMPLETED
ZDM_POST_MIGRATE_TGT .......... PENDING
ZDM_POSTUSERACTIONS ........... PENDING
ZDM_POSTUSERACTIONS_TGT ....... PENDING
ZDM_CLEANUP_SRC ............... PENDING
ZDM_CLEANUP_TGT ............... PENDING
Conclusion
- We learned that ZDM may sometimes try to reuse an existing GUID while converting DB to PDB
- This may be fixed natively in future releases of ZDM.
- I can’t assume this behavior would be the same in all cases, because I already moved databases to a CDB with many PDBs without any problem in the past
- Oracle documentation is explicit about the "AS CLONE" clause. Nevertheless, I don't think the same DB was migrated in the past to the same destination.
”SpecifyingASCLONEalso ensures that Oracle Database generates new identifiers(GUID,DBID) if the target CDB already contains a PDB that was created using the same set of data files” - You might not run into the same error, but this is the quickest fix in case it happens.
Thank you for reading


