Intro
This is the last of my troubleshooting series related to ZDM where I have accidentally become an unofficial QA tester for ZDM :). After describing scenarios in previous posts where ZDM service was crashing or DG configuration was failing. I will, in this article, explain why my broker switchover step failed the online physical migration and share a sneaky hack to skip a ZDM task during a zdmcli resume, after fixing it manually
(user discretion is advised).
My ZDM environment
ZDM: 21.3 build
| Property | Source | Target |
| RAC | NO | YES |
| Encrypted | NO | YES |
| CDB | NO | YES |
| Release | 12.2 | 12.2 |
| Platform | On prem Linux | ExaCC |
Prerequisites
All the prerequisites related to the ZDM VM, the Source and Target Database system were satisfied before running the migration.
Responsefile
Prepare a responsefile for a Physical Online Migration with the required parameters (see excerpt). I will just point out that ZDM 21.3 now supports Data Guard Broker configuration .
$ cat physical_online_demo.rsp | grep -v ^#
TGT_DB_UNIQUE_NAME=TGTCDB
MIGRATION_METHOD=ONLINE_PHYSICAL
DATA_TRANSFER_MEDIUM=DIRECT
PLATFORM_TYPE=EXACC
ZDM_USE_DG_BROKER=TRUE
...etc
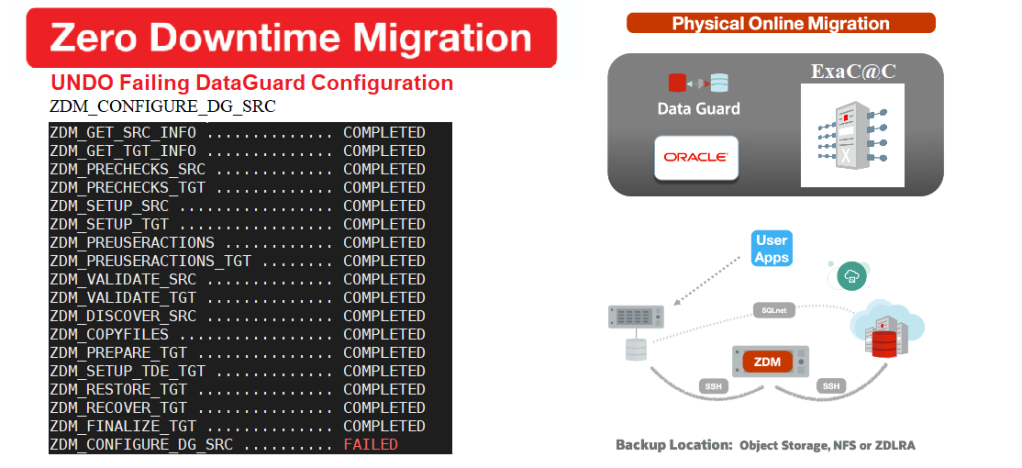
Run migration until the DG config –step1
Run migration until the DG config –step1
It is very common to run the migrate command with the -pauseafter ZDM_CONFIGURE_DG_SRC to stop when the replication is configured in order to resume the full migration a later time.
$ZDM_HOME/bin/zdmcli migrate database –sourcedb SRCDB \ -sourcenode srcHost -srcauth zdmauth \ -srcarg1 user:zdmuser \ -targetnode tgtNode \ -tgtauth zdmauth \ -tgtarg1 user:opc \ -rsp ./physical_online_demo.rsp –ignore ALL -pauseafter ZDM_CONFIGURE_DG_SRC
Resume migration –step2
Now that the Data guard Configuration is complete. It’s time to resume the full migration to the end.
$ zdmservice resume job –jobid 2
Querying job status
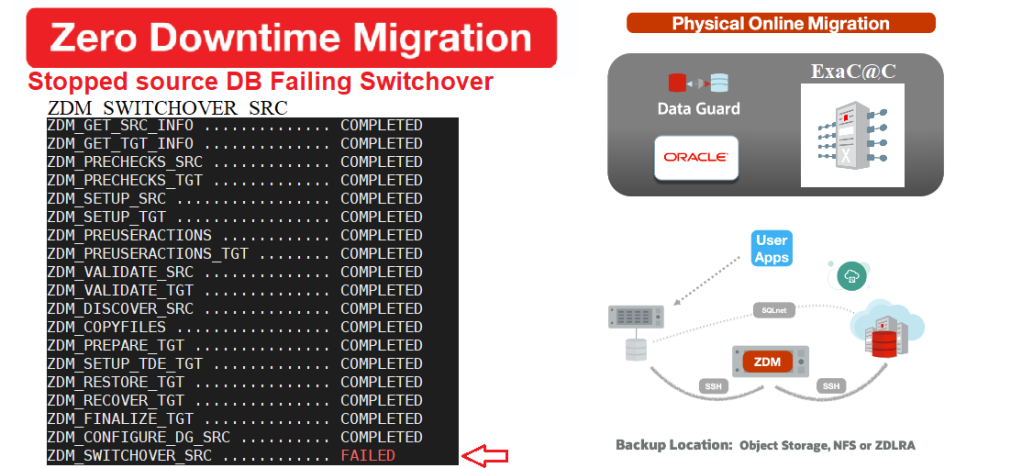
As you can see, It didn’t take long before noticing that the Switchover step failed.
$ zdmservice query job –jobid 2
zdmhost.domain.com: Audit ID: 39
Job ID: 2
User: zdmuser
Client: zdmhost
Job Type: "MIGRATE"
Current status: FAILED
Result file path: "/u01/app/oracle/zdmbase/chkbase/scheduled/job-2-*log" ...
Job execution elapsed time: 1 hours 25 minutes 41 seconds
ZDM_GET_SRC_INFO .............. COMPLETED
ZDM_GET_TGT_INFO .............. COMPLETED
ZDM_PRECHECKS_SRC ............. COMPLETED
ZDM_PRECHECKS_TGT ............. COMPLETED
ZDM_SETUP_SRC ................. COMPLETED
ZDM_SETUP_TGT ................. COMPLETED
ZDM_PREUSERACTIONS ............ COMPLETED
ZDM_PREUSERACTIONS_TGT ........ COMPLETED
ZDM_VALIDATE_SRC .............. COMPLETED
ZDM_VALIDATE_TGT .............. COMPLETED
ZDM_DISCOVER_SRC .............. COMPLETED
ZDM_COPYFILES ................. COMPLETED
ZDM_PREPARE_TGT ............... COMPLETED
ZDM_SETUP_TDE_TGT ............. COMPLETED
ZDM_RESTORE_TGT ............... COMPLETED
ZDM_RECOVER_TGT ............... COMPLETED
ZDM_FINALIZE_TGT .............. COMPLETED
ZDM_CONFIGURE_DG_SRC .......... COMPLETED
ZDM_SWITCHOVER_SRC ............ FAILED
ZDM_SWITCHOVER_TGT ............ PENDING
ZDM_POST_DATABASE_OPEN_TGT .... PENDING
ZDM_DATAPATCH_TGT ............. PENDING
ZDM_NONCDBTOPDB_PRECHECK ...... PENDING
ZDM_NONCDBTOPDB_CONVERSION .... PENDING
ZDM_POST_MIGRATE_TGT .......... PENDING
ZDM_POSTUSERACTIONS ........... PENDING
ZDM_POSTUSERACTIONS_TGT ....... PENDING
ZDM_CLEANUP_SRC ............... PENDING
ZDM_CLEANUP_TGT ............... PENDING
Troubleshooting
I usually like to dig into the specific $ZDM_BASE logs hosted locally in the src node, but the result file here is enough to investigate the failure as the log is pretty detailed.
$ tail /u01/app/oracle/zdmbase/chkbase/scheduled/job-2-*log
Executing Oracle Data Guard Broker switchover to database "zdm_aux_SRCDB"
on database "SRCDB" ... ####################################################################
PRGZ-3605 : Oracle Data Guard Broker switchover to database "zdm_aux_SRCDB"
on database "DB" failed.
Unable to connect to database using (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)
(HOST=srcnode)(PORT=1531)) …Please complete the following steps to finish switchover:
start up and mount instance "SRCDB" of database "SRCDB"
To be honest I am half surprised, since we used the DG Broker here and it’s known to be unstable at times during switchovers (had many failed switchovers due to tight connection timeouts on the old primary on ExaCC).
What Happened
The switchover actually completed but the source database didn’t restart after the role conversion. At least the suggested action is self explanatory and we don’t have to dig more to proceed with the rest of the migration.
Restart the new standby
SQL> startup mount;
Resume the job after restarting the new standby(src) ?
After confirming that the old primary (now standby) has restarted in mount mode, we can resume our job.
$ zdmservice resume job –jobid 2
Unfortunately, the job fails again at the same phase as before.
$ zdmservice query job –jobid 2
Type: "MIGRATE"
Current status: FAILED
…
ZDM_SWITCHOVER_SRC ............ FAILED
Why is ZDM failing after the Resume ?
It turns out ZDM was trying to restart the switchover again even if it was already done. This stopped the migration right there since the source Database role wasn’t Primary. But how do we skip a step in ZDM upon resume??
--- On the source
$ cd $ORACLE_BASE/zdm/zdm_SRCDB_$jobID/zdm/log
$ tail -f ./zdm_is_switchover_ready_src_29038.log
[mZDM_Queries.pm:564]:[DEBUG] Output is:qtag:PHYSICAL STANDBY:qtag: [mZDM_helper:240]:[ERROR] Database 'SRCDB' is not a PRIMARY database.
Solution: ZDM hack
---------------------------------------------DISCLAIMER----------------------------------------------------
Although the option to skip a migration step might be available in future releases of ZDM.
You should not perform the following on production unless explicitly advised by Oracle support.
Undocumented hack:
ZDM uses a checkpoint file to synchronize the status of each step between all members of the migration
It’s a simple xml file that is updated each time a phase state is changed. This file is also checked by ZDM anytime a resume command is called.
$ZDM_BASE/chkbase/GHcheckpoints/<source host>+<source db>+<target host>/
Example : cd $ZDM_BASE/chkbase/GHcheckpoints/srcNode+SRCDB+targetNode/
$ vi srcNode+SRCDB+targetNode.xml<CHECKPOINT LEVEL="MAJOR" NAME="ZDM_SWITCHOVER_SRC" DESC="ZDM_SWITCHOVER_SRC"
STATE="START"/> ---> REPLACE STATE AS FOLLOWS <CHECKPOINT LEVEL="MAJOR" NAME="ZDM_SWITCHOVER_SRC" DESC="ZDM_SWITCHOVER_SRC"
STATE="SUCCESS"/>
Resume the job
Voila, ZDM will now skip the switchover after resuming the job to complete the rest of our online physical migration
$ zdmservice resume job –jobid 2
$ zdmservice query job –jobid 2
...
ZDM_CONFIGURE_DG_SRC .......... COMPLETED
ZDM_SWITCHOVER_SRC ............ COMPLETED
ZDM_SWITCHOVER_TGT ............ PENDING
ZDM_POST_DATABASE_OPEN_TGT .... PENDING
ZDM_DATAPATCH_TGT ............. PENDING
ZDM_NONCDBTOPDB_PRECHECK ...... PENDING
ZDM_NONCDBTOPDB_CONVERSION .... PENDING
ZDM_POST_MIGRATE_TGT .......... PENDING
ZDM_POSTUSERACTIONS ........... PENDING
ZDM_POSTUSERACTIONS_TGT ....... PENDING
ZDM_CLEANUP_SRC ............... PENDING
ZDM_CLEANUP_TGT ............... PENDING
Conclusion
- In this scenario, we tricked ZDM into skipping the switchover stage as it was already done
- Big thanks to ZDM team for being very responsive on my migration qualms as always
- This is an interesting scenario because ZDM usually has only a rerun feature but not a skip option
- Also, I didn’t have this problem when DG_BROKER wasn’t enabled in another ZDM migration
- Like l said I’ve been told the introduction of such feature is most likely in the future, so stay tuned
- Hope this will help anyone who runs into the same error to quickly fix it and go on with the migration
Thank you for reading